How to Test Computer Vision Systems (Part 1 of 2)
By Dr. Zain Masood
In this two part blog, we want to explore how to test a Computer Vision system. We will do a deep dive into the process and best practices for properly and accurately run a computer vision test. The first part here will cover Annotation. Data annotation helps provide valuable insight and information with respect to the system requirements.The second part will cover evaluation and explain topics like accuracy, recall and precision.
Part 1: Annotation
Overview
The purpose of a Computer Vision System, especially one based on machine learning and deep learning, is to analyze visual data in a humanly manner. What this means is that such a system should have the ability to perceive the data as a human would and come to the same conclusion as a human would draw from it.
Let us take the following image as an example.

How do humans perceive this image? We create hierarchies of descriptions where our brain picks up on the low-level details of where/what objects are present in the scene (dog, bicycle, tree, car, etc) as well as high-level details of what the scene represents as collections or as a whole (home, porch, street, sunny, etc).
Depending on the use case, any or all of the above answers are correct. The “correctness” of the responses merely depend on how the CV system was trained. Hence, it should be evaluated, against human responses, on the same metrics.
In this blog, we will do a deep dive into the process and best practices for properly and accurately testing a CV system. We will list the steps needed to achieve this goal and provide details on what each of them encapsulates. Following is a bulleted list of the sequential steps highlighting the testing process:
Test data collection
Test data annotation
Classification Annotation
Detection Annotation
Annotation Format
Test data evaluation
Test Data Collection
The first phase in testing a computer vision system is properly defining the data that would be used for testing. This is important because the focus of this exercise is two fold:
This data collection, to the satisfaction of the end-user, comprises images/videos that cover the use case scenario under all expected varying conditions (lighting, angle, occlusion, size, etc). This is important as it exhibits the performance of the computer vision system for the specific use case scenario as well as the robustness of the algorithm given varying conditions.
From a provider’s perspective, constructing such a test set allows the R&D team to clearly define the success/failure criteria. Furthermore, it enables them to evaluate the system in a deterministic manner and help tweak/tune parameters to improve performance and efficiency of the system.

Test Data Annotation
Once the test data is defined, collected and agreed upon, the next task is to annotate it for evaluation purposes. Data annotation helps provide valuable insight and information with respect to the system requirements. Essentially, the goal is to highlight the presence of key objects in the data. The data annotation process is labor-intensive where real human beings analyze images/videos and perform the necessary tasks (tagging, drawing boxes, etc). These annotation tasks differ based on the functionality offered and the type of result output the system is expected to return. Below we discuss the most common system capabilities and their corresponding annotation requirements.
Classification Annotation
The classification task can be described as a technique of identifying image-level/video-level tags. These tags can range anywhere from low-level object-specific information highlighting the presence of certain objects in the data OR high-level concept-specific information describing the scene. Each image/video can have one or more tags associated with it. For the example shown below, the following image-level tags could be construed:

Detection Annotation
There are three key fundamentals for detection annotation:
Requires only low-level (object) tags. High-level (concept) tags are not needed.
Knowing which objects are present in the data
Knowing where objects are located in the data
In other words, detection annotation comprises low-level object-specific tags with the added information of the position and size of the object in the data. This aligns with the task of detection where the system needs to determine the placement and dimensions of each key object (highlighted using a bounding box approach) and assign the appropriate label to it (person, face, car, license plate, etc). Using the same example, the following rendering shows the annotation details for the detection task.
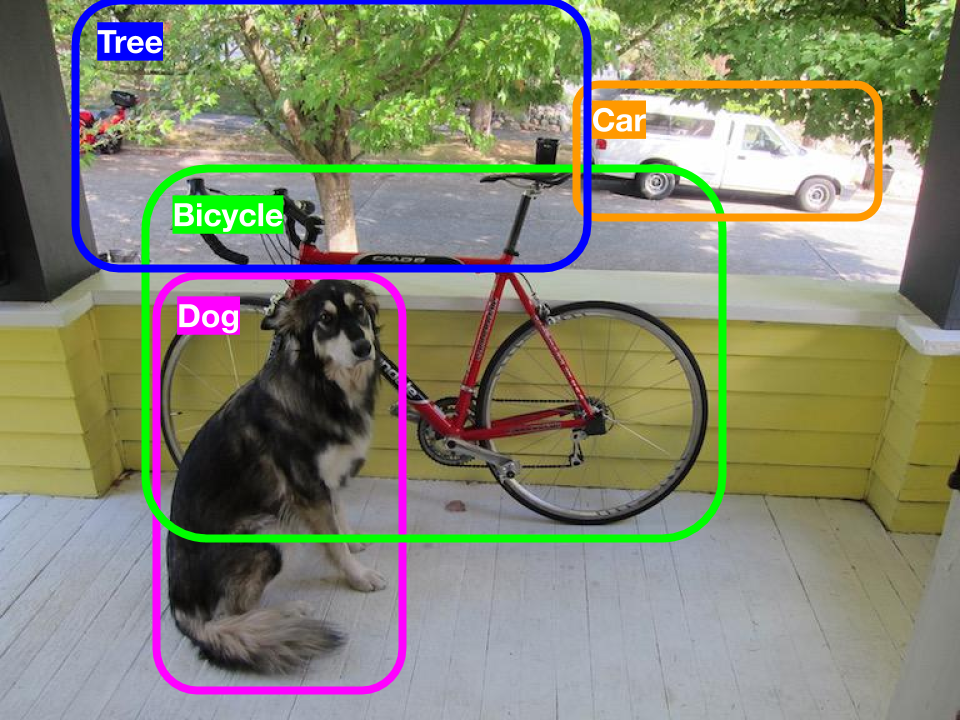
Annotation Format
The annotations can be saved out in any number of formats (txt, csv, xml, json, etc). For our tasks, we generally prefer the JSON format as it is much more manageable and flexible. Following is an annotation file sample in JSON format:

Conclusion
The purpose of the Computer Vision System, especially one based on machine learning and deep learning, is to analyze visual data in a humanly manner. The first phase in testing a computer vision system is properly defining the data that would be used for testing. Once the test data is defined, collected and agreed upon, the next task is to annotate it for evaluation purposes. The data annotation process is labor-intensive where real human beings analyze images/videos and perform the necessary tasks (tagging, drawing boxes, etc). These annotation tasks differ based on the functionality offered and the type of result output the system is expected to return. There are three key fundamentals for detection annotation
Requires only low-level (object) tags. High-level (concept) tags are not needed.
Knowing which objects are present in the data
Knowing where objects are located in the data